 21:58
21:58
 RAM KUMAR LANKE
RAM KUMAR LANKE
FRIDAY, 20 MAY 2011
Dynamically set an integration interface source set name at run time
Hi Guru’s,
Hope you are fine.
Suppose if we have multiple files of same structure to be loaded into a single target table, then we need not to use multiple interfaces.
Instead we can use a single interface to load all the flat files of same structure into the single target table.
I am going to try to explain the procedure with following steps
Suppose if we have three Flat files namely EMP1.txt, EMP2.txt and EMP3.txt to be loaded into TRG_EMP table of ORACLE database.
Before going to do this, you need to learn first how to load a single source flat file to a target table of oracle database.
To do the above please go through the following link provided by oracle by examples
ODI11g: Creating an ODI Project and Interface: Exporting a Flat File to a RDBMS Table
Using the above procedure load the EMP.txt file to
EMP table .
you can download the required files from the following link
Download source files
Now follow the following steps.
First we need to create a table using the following query
CREATE TABLE SRC_FILE_DETAILS
( FILE_NAME VARCHAR2(10 BYTE)
);
Then load the required file names into this table.
INSERT INTO src_file_details values 'EMP1'
INSERT INTO src_file_details values 'EMP2'
INSERT INTO src_file_details values 'EMP3'
Now create three variables with the following deatails
1) Name: count
Data type: Numeric
Action : latest Value
2) Name: Files_Count
Datatype: Numeric
Action: latest Value
Refreshing: select count(*) from src_file_details
3) Name: FILE_NAME
Datatype: Alphanumeric
Action: Latest value
Refreshing:
SELECT FILE_NAME FROM (SELECT FILE_NAME,ROWNUM RN FROM SRC_FILE_DETAILS) WHERE RN=#Project_Name.count
Note: Please replace Project_Name with your project name
Now open the source data store which is participating in the interface for populating target and replace the resource name with #Project_Name.FILE_NAME.txt

Now we are going to design a package looks like below:

Step1:
Drag and drop the count variable on to the diagram tab of package.
Click on it. Change the properties as shown in the following

Step2: Drag and drop the FILE_NAME variable on to the diagram tab of package.
Click on it. Change the properties as shown in the following
Step name: GetTheFileName
Type: Refresh variable
Step3:
Just drag and drop the interface and change the step name to PopTrgWithThisFileName
Step4:
Drag and drop the count variable.
Click on it. Change the properties as shown in the following

Step5:
Step type : Refresh Variable
Step6:
Drag and drop the count variable on to the diagram tab of package.
Click on it. Change the properties as shown in the following
Drag and drop the Files_Count variable.
Click on it. Change the properties as shown in the following
Step type : Refresh Variable
Step6:
Drag and drop the count variable on to the diagram tab of package.
Click on it. Change the properties as shown in the following

Please replace Proj_Name with your project name
Save all
Run the package
That it.
Now life is so easy.
You can load a table with several files with single interface.
Thanks Guru’s
Ram Kumar Lanke
Running parallel ODI interfaces
Hi Guru,
We know that ODI derives the names of temporary tables from the name of the datastore.
As a result conflicts between multiple simultaneous integration interfaces can arise.
In order to avoid such problems when we are executing parallel scenarios we have to modify the data server to use the ODI Package variables to store prefixes to be used for integration interfaces.
The following steps explain how to do it.
1. Go to the topology manager
2. Edit the physical schema of this target data store
3. In the definition tab,
Replace the existing values set for temporary table prefixes with the name of the ODI package variables.
4. Launch your integration interface from a package in which the ODI variable is declared at the begining.
Thanks Guru,
Ram kumar Lanke
We know that ODI derives the names of temporary tables from the name of the datastore.
As a result conflicts between multiple simultaneous integration interfaces can arise.
In order to avoid such problems when we are executing parallel scenarios we have to modify the data server to use the ODI Package variables to store prefixes to be used for integration interfaces.
The following steps explain how to do it.
1. Go to the topology manager
2. Edit the physical schema of this target data store
3. In the definition tab,
Replace the existing values set for temporary table prefixes with the name of the ODI package variables.
4. Launch your integration interface from a package in which the ODI variable is declared at the begining.
Thanks Guru,
Ram kumar Lanke
Modifying ODI integration table prefixes
Hi Guru,
We know that ODI derives the names of temporary tables from the name of the datastore.
As a result conflicts between multiple simultaneous integration interfaces can arise.
In order to avoid such problems when we are executing parallel scenarios we have to modify the data server to use the ODI Package variables to store prefixes to be used for integration interfaces.
The following steps explain how to do it.
1. Go to the topology manager
2. Edit the physical schema of this target data store
3. In the definition tab,
Replace the existing values set for temporary table prefixes with the name of the ODI package variables.
4. Launch your integration interface from a package in which the ODI variable is declared at the begining.
Thanks Guru,
Ram kumar Lanke
We know that ODI derives the names of temporary tables from the name of the datastore.
As a result conflicts between multiple simultaneous integration interfaces can arise.
In order to avoid such problems when we are executing parallel scenarios we have to modify the data server to use the ODI Package variables to store prefixes to be used for integration interfaces.
The following steps explain how to do it.
1. Go to the topology manager
2. Edit the physical schema of this target data store
3. In the definition tab,
Replace the existing values set for temporary table prefixes with the name of the ODI package variables.
4. Launch your integration interface from a package in which the ODI variable is declared at the begining.
Thanks Guru,
Ram kumar Lanke
SATURDAY, 7 MAY 2011
Introduction to Integration Interfaces
An integration interface is an Oracle Data Integrator object stored that enables the loading of one target datastore with data transformed from one or more source datastores, based on declarative rules implemented as mappings, joins, filters and constraints.
An integration interface also references the Knowledge Modules (code templates) that will be used to generate the integration process.
Datastores
A datastore is a data structure that can be used as a source or a target in an integration interface. It can be:
a table stored in a relational database
an ASCII or EBCDIC file (delimited, or fixed length)
a node from a XML file
a JMS topic or queue from a Message Oriented Middleware
a node from a enterprise directory
an API that returns data in the form of an array of records
Regardless of the underlying technology, all data sources appear in Oracle Data Integrator in the form of datastores that can be manipulated and integrated in the same way. The datastores are grouped into data models. These models contain all the declarative rules –metadata - attached to datastores such as constraints.
Declarative Rules
The declarative rules that make up an interface can be expressed in human language, as shown in the following example: Data is coming from two Microsoft SQL Server tables (ORDERS joined to ORDER_LINES) and is combined with data from the CORRECTIONS file. The target SALES Oracle table must match some constraints such as the uniqueness of the ID column and valid reference to the SALES_REP table.
Data must be transformed and aggregated according to some mappings expressed in human language as shown in Figure: Example of a business problem.


Data Flow
Business rules defined in the interface are automatically converted into a data flow that will carry out the joins filters, mappings, and constraints from source data to target tables.
By default, Oracle Data Integrator will use the Target RBDMS as a staging area for loading source data into temporary tables and applying all the required mappings, staging filters, joins and constraints. The staging area is a separate area in the RDBMS (a user/database) where Oracle Data Integrator creates its temporary objects and executes some of the rules (mapping, joins, final filters, aggregations etc.). When performing the operations this way, Oracle Data Integrator behaves like an E-LT as it first extracts and loads the temporary tables and then finishes the transformations in the target RDBMS.
In some particular cases, when source volumes are small (less than 500,000 records), this staging area can be located in memory in Oracle Data Integrator's in-memory relational database – In-Memory Engine. Oracle Data Integrator would then behave like a traditional ETL tool.
Figure: Oracle Data Integrator Knowledge Modules in action shows the data flow automatically generated by Oracle Data Integrator to load the final SALES table. The business rules will be transformed into code by the Knowledge Modules (KM). The code produced will generate several steps. Some of these steps will extract and load the data from the sources to the staging area (Loading Knowledge Modules - LKM). Others will transform and integrate the data from the staging area to the target table (Integration Knowledge Module - IKM). To ensure data quality, the Check Knowledge Module (CKM) will apply the user defined constraints to the staging data to isolate erroneous records in the Errors table.

Oracle Data Integrator Knowledge Modules contain the actual code that will be executed by the various servers of the infrastructure. Some of the code contained in the Knowledge Modules is generic. It makes calls to the Oracle Data Integrator Substitution API that will be bound at run-time to the business-rules and generates the final code that will be executed.
At design time, declarative rules are defined in the interfaces and Knowledge Modules are only selected and configured.
At run-time, code is generated and every Oracle Data Integrator API call in the Knowledge Modules (enclosed by <% and %>) is replaced with its corresponding object name or expression, with respect to the metadata provided in the Repository. The generated code is orchestrated by Oracle Data Integrator run-time component - the Agent – on the source and target systems to make them perform the processing, as defined in the E-LT approach.
Faster way to create interfaces
Hi Guru's,
Today we concentrate on how to create interfaces quickly.
The ODI 11g has a feature calle Interfaces IN , using this feature we can create interfaces quickly.
To generate the Interfaces IN:
In the Models tree of Designer Navigator, select the data model or datastore for which you want to generate the interfaces.
Right-click, then select Generate Interfaces IN. Oracle Data Integrator looks for the original datastores and columns used to build the current model or datastore. The Generate Interfaces IN Editor appears with a list of datastores for which Interfaces IN may be generated.


Select an Optimization Context for your interfaces. This context will define how the flow for the generated interfaces will look like, and will condition the automated selection of KMs.
Click the ... button to select the Generation Folder into which the interfaces will be generated.

In the Candidate Datastores table, check the Generate Interface option for the datastores to load.
Edit the content of the Interface Name column to rename the integration interfaces.
Click OK. Interface generation starts.
The generated interfaces appear in the specified folder.

Note: Interfaces automatically generated are built using predefined rules based on repository metadata. These interfaces can not be executed immediately. They must be carefully reviewed and modified before execution
Note: If no candidate datastore is found when generating the interfaces IN, then it is likely that the datastores you are trying to load are not built from other datastores or columns. Automatic interface generation does not work to load datastores and columns that are not created from other model's datastores and columns.
Thanks Guru's
Ram Kumar Lanke
Today we concentrate on how to create interfaces quickly.
The ODI 11g has a feature calle Interfaces IN , using this feature we can create interfaces quickly.
To generate the Interfaces IN:
In the Models tree of Designer Navigator, select the data model or datastore for which you want to generate the interfaces.
Right-click, then select Generate Interfaces IN. Oracle Data Integrator looks for the original datastores and columns used to build the current model or datastore. The Generate Interfaces IN Editor appears with a list of datastores for which Interfaces IN may be generated.


Select an Optimization Context for your interfaces. This context will define how the flow for the generated interfaces will look like, and will condition the automated selection of KMs.
Click the ... button to select the Generation Folder into which the interfaces will be generated.

In the Candidate Datastores table, check the Generate Interface option for the datastores to load.
Edit the content of the Interface Name column to rename the integration interfaces.
Click OK. Interface generation starts.
The generated interfaces appear in the specified folder.

Note: Interfaces automatically generated are built using predefined rules based on repository metadata. These interfaces can not be executed immediately. They must be carefully reviewed and modified before execution
Note: If no candidate datastore is found when generating the interfaces IN, then it is likely that the datastores you are trying to load are not built from other datastores or columns. Automatic interface generation does not work to load datastores and columns that are not created from other model's datastores and columns.
Thanks Guru's
Ram Kumar Lanke
Components of an Integration Interface
An integration interface is made up of and defined by the following components:
Target Datastore
The target datastore is the element that will be loaded by the interface. This datastore may be permanent (defined in a model) or temporary (created by the interface).
Datasets One target is loaded with data coming from several datasets. Set-based operators (Union, Intersect, etc) are used to merge the different datasets into the target datastore.
Each Dataset corresponds to one diagram of source datastores and the mappings used to load the target datastore from these source datastores.
Diagram of Source Datastores
A diagram of sources is made of source datastores - possibly filtered - related using joins. The source diagram also includes lookups to fetch additional information for loading the target.
Two types of objects can be used as a source of an interface: datastores from the models and interfaces. If an interface is used, its target datastore -temporary or not- will be taken as a source.
The source datastores of an interface can be filtered during the loading process, and must be put in relation through joins. Joins and filters are either copied from the models or can be defined for the interface. Join and filters are implemented in the form of SQL expressions.
Mapping
A mapping defines the transformations performed on one or several source columns to load one target column. These transformations are implemented in the form of SQL expressions. Each target column has one mapping per dataset. If a mapping is executed on the target, the same mapping applies for all datasets.
Staging Area
The staging area is a logical schema into which some of the transformations (joins, filters and mappings) take place. It is by default the same schema as the target's logical schema.
It is possible to locate the staging area on a different location (including one of the sources). It is the case if the target's logical schema is not suitable for this role. For example, if the target is a file datastore, as the file technology has no transformation capability.
Mappings can be executed either on the source, target or staging area. Filters and joins can be executed either on the source or staging area.
Flow
The flow describes how the data flows between the sources, the staging area if it is different from the target, and the target as well as where joins and filters take place. The flow also includes the loading and integration methods used by this interface. These are selected by choosing Loading and Integration Knowledge Modules (LKM, IKM).
Control
An interface implements two points of control. Flow control checks the flow of data before it is integrated into the target, Post-Integration control performs a static check on the target table at the end of the interface. The check strategy for Flow and Post-Integration Control is defined by a Check Knowledge Module (CKM).
Common errors while developing interfaces
Hi Guru's,
Let us know the common errors we get after executing the interfaces
Thanks Guru's
Ram Kumar Lanke
Let us know the common errors we get after executing the interfaces
- Syntax error in join condition
- Syntax error in filter condition
- Obvious error appears in a SELECT/INSERT or WHERE clause
- Errors like Column does not exist
- Syntax error
- Incorrect execution location for join condition
- Incorrect execution location for filter condition
- A valid clause cannot be executed
- A clause located at the wrong location (source/target)
- Data servers unreachable
- Tables/files/resources does not exist
- Table not found
- Irrelevant results
Thanks Guru's
Ram Kumar Lanke
Using Operator to dubug interfaces
Hi Guru's,
Let us discuss about how to use operator navigator to debug interfaces.
The operator navigator is used for the following
The Session List accordion displays all sessions organized per date, physical agent, status, keywords, and so forth.
Hierarchical Sessions
The Hierarchical Sessions accordion displays the execution sessions organized in a hierarchy with their child sessions.
Scheduling
The Scheduling accordion displays the list of physical agents and schedules.
Scenarios
The Scenarios accordion displays the list of scenarios available.
Solutions
The Solutions accordion contains the Solutions that have been created when working with version management.
How ever a session may also contain several interface steps and other steps like variables , procedures, scenarios, odi tools etc,.
I will discuss later how to debug other sessions.
Operator serves primarily to show the executions log of the interfaces that you executed.
Other sessions such as packages are also visable, but let me concentarte now on interface sessions.
When you execute an interface, a session will be automatically created.
Then you have to find the session in the operator log.
1) Locate the interface session



2) Check the session state

3) Double click the session check the properties

4) If there is no error , check the number of processed rows in the deatails
5) If there is error start trouble shooting.( discussed in another post click here to view it. )
6) Identify the error task of the session. This task is found in the session with an error icon.
7) Double click the task to see the generated code
8) Fix the code by editing the code in the task.

9) Click the link query/execution plan link on the top right side.And run the code. Or you can also copy the code into an external SQL analysis tool. Make necessary change in the code if required.
10) Save by clicking close
11) Restart the session.

12) After if you fix the error apply the changes to the interface and re execute the interface.
Thanks Guru's
Ram Kumar Lanke
Let us discuss about how to use operator navigator to debug interfaces.
The operator navigator is used for the following
- Use to work with your scenarios, sessions, and schedules in Oracle Data Integrator.
- The Operator Navigator stores this information in a work repository.
- The Operator Navigator has the following accordions:
- Session List
- Hierarchical Sessions
- Scheduling
- Scenarios
- Solutions


The Session List accordion displays all sessions organized per date, physical agent, status, keywords, and so forth.
Hierarchical Sessions
The Hierarchical Sessions accordion displays the execution sessions organized in a hierarchy with their child sessions.
Scheduling
The Scheduling accordion displays the list of physical agents and schedules.
Scenarios
The Scenarios accordion displays the list of scenarios available.
Solutions
The Solutions accordion contains the Solutions that have been created when working with version management.
Let me explain how we use operator to debug interface session step by step.
I will discuss later how to debug other sessions.
Operator serves primarily to show the executions log of the interfaces that you executed.
Other sessions such as packages are also visable, but let me concentarte now on interface sessions.
When you execute an interface, a session will be automatically created.
Then you have to find the session in the operator log.
1) Locate the interface session
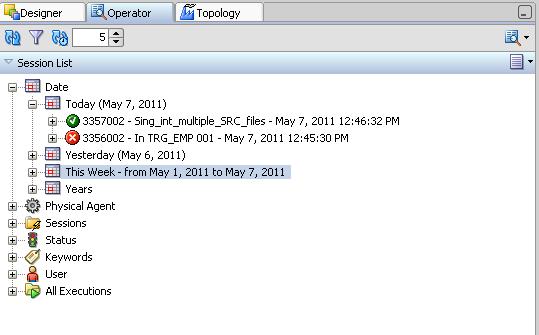


2) Check the session state

3) Double click the session check the properties

4) If there is no error , check the number of processed rows in the deatails
5) If there is error start trouble shooting.( discussed in another post click here to view it. )
6) Identify the error task of the session. This task is found in the session with an error icon.
7) Double click the task to see the generated code
8) Fix the code by editing the code in the task.

9) Click the link query/execution plan link on the top right side.And run the code. Or you can also copy the code into an external SQL analysis tool. Make necessary change in the code if required.
10) Save by clicking close
11) Restart the session.

Thanks Guru's
Ram Kumar Lanke
Debugging Interfaces
Hi Guru's,
Today we are going to learn how to debug interfaces.
We use operator to monitor the execution of an interface.
Run (execute ) the Pop. TRG_SALES integration interface

How to monitor execution of an interface?
Click here to read it.
Thanks Guru's
Ram kumar Lanke
Today we are going to learn how to debug interfaces.
We use operator to monitor the execution of an interface.
- When ever we run the interface the odi creates a session to execute it.
- In other words each time an interface is executed, a session is created.
- The interface corresponds to only one step.
- And each interface step may contain several tasks.
- A task may do the tasks like:
- Reading data from a table
- Writing data to a file
- Creating tables
- Deleting tables
- Loading data into table or file
- Checking for flow
- Data quality checks
- etc,
- Such series of tasks are depend upon entirely the Knowledge modules which you have choosen for your interface
- Each task will be one state at any moment.
- The possible states are Done, Error, Running, Waiting, Queued and Warning
Run (execute ) the Pop. TRG_SALES integration interface
Follow the Execution of the Interface in Operator Navigator
To view the execution results of your integration interface:- In the Session List accordion in Operator Navigator, expand the All Executions node.
- Refresh the displayed information clicking Refresh in the Operator Navigator toolbar menu.
- The log for the execution session of the Pop. TRG_SALES interface appears as shown in figure
Figure Pop. TRG_SALES Interface Session Log
The status of a session may be in running state, suckles state, waiting state or error state.
Viewing the Results
Each interface session has the following Properties

FigurRecord Statistics in the Session Step Editor
How to monitor execution of an interface?
- Find the session of the interface in the operator
- Double click the session to view the properties
- If the state is not error check the number of rows processed
- Check the valid and erroneous rows you expected
- If the case is error or the number of rows processed are not you expecting, then start trobleshooting
Click here to read it.
Thanks Guru's
Ram kumar Lanke
FRIDAY, 6 MAY 2011
MULTIPLE SOURCE FILES-MULTIPLE TARGET TABLES-SINGLE INTERFACE
Hi Guru’s,
We have seen in the last post how to load multiple source files of same structure into a single table.
Suppose if we want to load multiple source files into multiple target tables.
Then please just follow the same procedure which I explained in the previous post and do a little change to the target data store.
Open the source data store which is participating of the interface and replace the resource name with #Project_Name.FILE_NAME
Note : Project_Name means your project name
Note : Project_Name means your project name
That’s it .
Thanks Guru's
Ram Kumar Lanke
Thanks Guru's
Ram Kumar Lanke
MULTIPLE FILES - SINGLE TARGET TABLE-SINGLE INTERFACE
Hi Guru’s,
Hope you are fine.
Today let me share very important concept of ODI called using Variable as Resource name.
Suppose if we have multiple files of same structure to be loaded into a single target table, then we need not to use multiple interfaces.
Instead we can use a single interface to load all the flat files of same structure into the single target table.
I am going to try to explain the procedure with following steps
Suppose if we have three Flat files namely EMP1.txt, EMP2.txt and EMP3.txt to be loaded into TRG_EMP table of ORACLE database.
Before going to do this, you need to learn first how to load a single source flat file to a target table of oracle database.
To do the above please go through the following link provided by oracle by examples
ODI11g: Creating an ODI Project and Interface: Exporting a Flat File to a RDBMS Table
Using the above procedure load the EMP.txt file to
EMP table .
you can download the required files from the following link
Download source files
Now follow the following steps.
First we need to create a table using the following query
CREATE TABLE SRC_FILE_DETAILS
( FILE_NAME VARCHAR2(10 BYTE)
);
Then load the required file names into this table.
INSERT INTO src_file_details values 'EMP1'
INSERT INTO src_file_details values 'EMP2'
INSERT INTO src_file_details values 'EMP3'
Now create three variables with the following deatails
1) Name: count
Data type: Numeric
Action : latest Value
2) Name: Files_Count
Datatype: Numeric
Action: latest Value
Refreshing: select count(*) from src_file_details
3) Name: FILE_NAME
Datatype: Alphanumeric
Action: Latest value
Refreshing:
SELECT FILE_NAME FROM (SELECT FILE_NAME,ROWNUM RN FROM SRC_FILE_DETAILS) WHERE RN=#Project_Name.count
Note: Please replace Project_Name with your project name
Now open the source data store which is participating in the interface for populating target and replace the resource name with #Project_Name.FILE_NAME.txt
Now we are going to design a package looks like below:
Step1:
Drag and drop the count variable on to the diagram tab of package.
Click on it. Change the properties as shown in the following
Step2: Drag and drop the FILE_NAME variable on to the diagram tab of package.
Click on it. Change the properties as shown in the following
Step name: GetTheFileName
Type: Refresh variable
Step3:
Just drag and drop the interface and change the step name to PopTrgWithThisFileName
Step4:
Drag and drop the count variable.
Click on it. Change the properties as shown in the following
Step5:
Drag and drop the Files_Count variable.
Click on it. Change the properties as shown in the following
Step type : Refresh Variable
Step6:
Drag and drop the count variable on to the diagram tab of package.
Click on it. Change the properties as shown in the following
Drag and drop the Files_Count variable.
Click on it. Change the properties as shown in the following
Step type : Refresh Variable
Step6:
Drag and drop the count variable on to the diagram tab of package.
Click on it. Change the properties as shown in the following
Please replace Proj_Name with your project name
Save all
Run the package
That it.
Now life is so easy.
You can load a table with several files with single interface.
Thanks Guru’s
Ram Kumar Lanke



0 comments:
Post a Comment